Diversifying Options in Option-Critic Framework of Hierarchical Reinforcement Learning
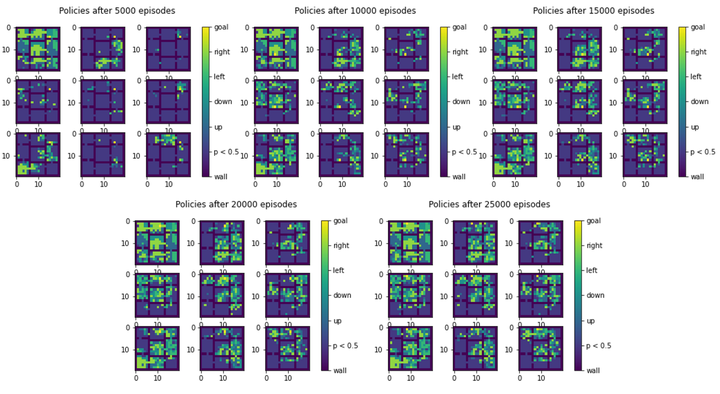 Policy visualization for a simple 9-room environment setting.
Policy visualization for a simple 9-room environment setting.Reinforcement learning has achieved great successes in many different domains recent years. However, it remains a big challenge for these method to address environments with sparse and delayed rewards, which are often encounter in real world scenarios. As an innovative approach to solve this problem, Hierarchical Reinforcement Learning manages to learn knowledge at multiple levels and make plans with temporal abstraction. In addition to its great performance on sparse reward problems, previous researches have also revealed its potential of transfer learning.
Two main approaches have been proposed for designing HRL architectures. The first one is to find and assign subgoals to guide the low level policy. The other one is to learn skills on the low level policy and a policy to utilize these skills on the higher level.
In our research, we focus on the option framwork as a representative of the second approach. We implement the Option-Critic architecture and reproduce its result on maze problems. During experiments, however, we find the natural tendency of the agent to develop only one option for the whole problem, which essentially degrades to vanilla policy gradient method. We are therefore motivated to develop methods to enhance the diversity of options. We consider several possible methods including dropouts on options, giving intrinsic rewards to guide the choice of options and enhancing option specialization on termination probability.